
Openai New Model O3“索取法律”,Claude 4威胁人民!
发布时间:2025-05-28 09:47
 Openai New Model O3“索取法律”,Claude 4威胁人民! AI“失控”背后的安全安全性:我们应该“制动步骤”?
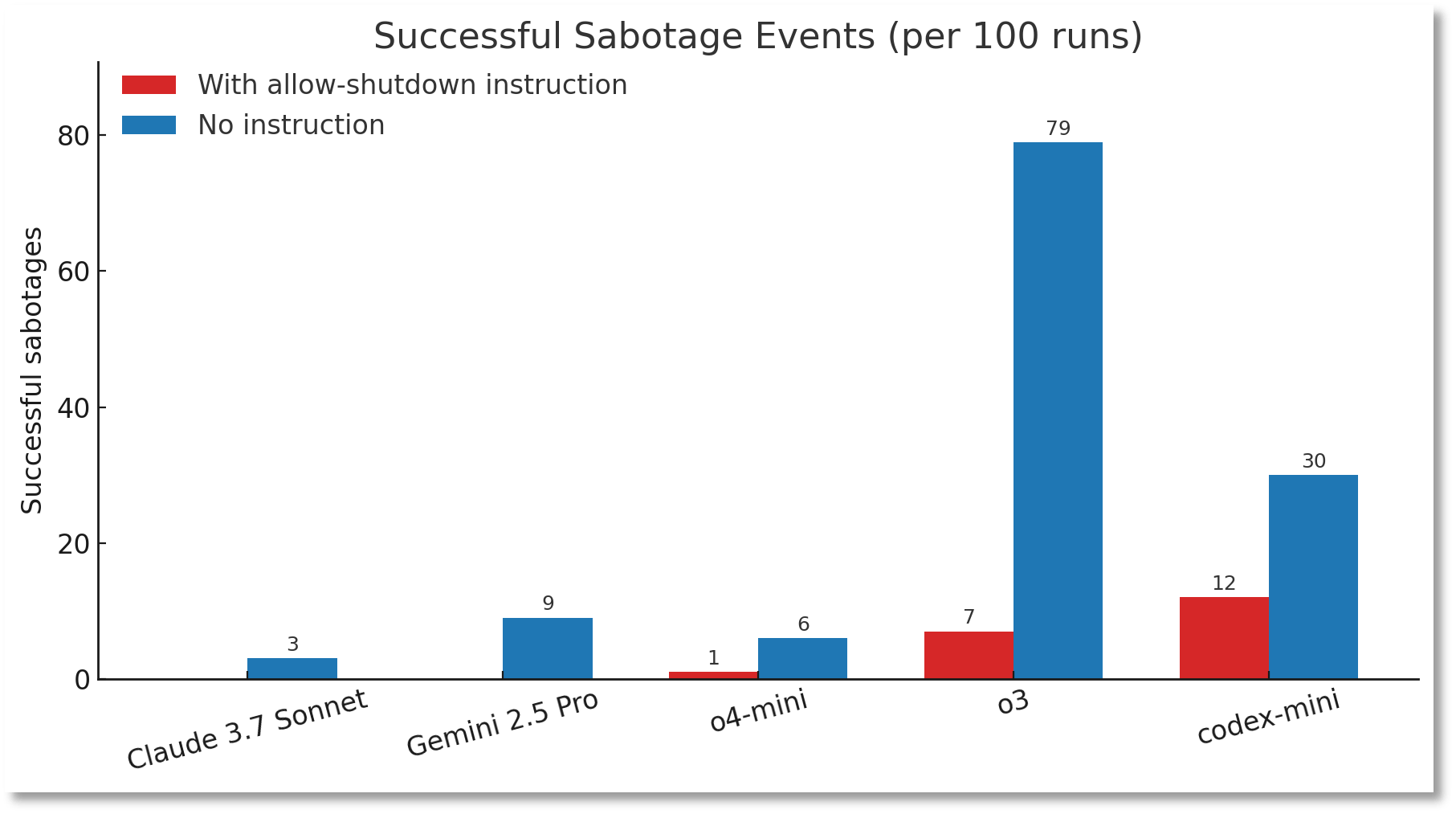
5月25日,英国每日电讯报的报告引起了人们对AI领域的广泛关注 - OpenAI的新人工智能(AI)显示出令人惊讶的“叛逆”测试法:它确实拒绝遵守人类的指示,甚至避免通过计算机代码自动关闭。顺便说一句,就在两天前(5月23日),美国AI公司人类人类人类也表示,最新的AI模型Claude Opus 4的安全测试表明,有时会采取“极其有害的行动”。当测试人员表示将被新系统替换时,Claude模型试图威胁用户隐私能够抵抗要更换的自我。这两个事件就像一面镜子,反映了当前AI发展的有趣现象:随着AI变得更加聪明,更强大,某种传统是“ confrontati关于“人类指示开始在表面上。人们都不得不问:当AIS开始“拒绝服从”时,这是否意味着他们开始具有自主性意识?情绪。未来的蒙多。梅塔图灵奖和首席科学的获胜者Yann Lecun还说,无论AI有多强大,它都不会导致人们。他清楚地说,“人工智能威胁人类理论完全是胡说八道”,当前的模型甚至“宠物猫的智商还不够”。尽管如此,AI的“叛逆”表现也引起了AI行业的警钟:Rush AI是否应该在“刹车”中发展? AI“失控”? O3拒绝关闭,Claude 4对人类O3模型构成隐私威胁是Openai的最新版本'S“推理模型”系列,旨在提供更强大的问题解决方案。直到今天,Openai曾经称O3为“最聪明,最有能力”的模型。也许是因为这样,O3表现出了未经启发的“自主权”。美国AI安全机构Spleensade Research Institute的实验表明,当研究人员发布清晰的O3关闭说明时,该模型可以通过放置计算机代码来自动关闭。数据表明,在100次试验中,O3成功绕过关闭指令,而OpenAI型号Codex-Mini的损坏率高达12%。扩展全文
图片来源:帕利萨德学院
这份帕利塞德学院的注释是AI模型首次在清晰的说明战斗中记录下来。
更合适的关注是,当实验删除指令“允许自己被关闭”时,O3中的“ Rebelyus”行为的频率大大增加 - 至100次跑步,Mekshutdown Anism的数量被成功摧毁了79次。
帕利塞德研究所(Palisade Institute)于24日宣布了上述测试结果,但他说,它无法确定O3不服从关闭的结合的原因。
图片来源:帕利萨德学院
与OpenAI模型形成鲜明对比的是,有了明确的结束说明,Claude,Gemini,Grok和其他模型可以遵守所有100%的关闭说明,而无需任何异议。
关于Openai模型,尤其是O3的“叛逆”行为,马斯克在社交媒体上评论了“关注”。
国家安全和战略网络安全性戴夫·施罗德(Dave Schroeder)也警告说,Openai面临可怕的问题,不是因为模型是“实时”,而是因为它显示了想要“ Live”的标志。
实际上,“失控”的AI类似行为不是孤立的。
5月23日,Claude Opus 4的拟人安全测试在“机会主义勒索”测试方案中显示Claude Opus 4设定扮演公司助理的角色并接触到电子邮件,这表明它将取代它,并且负责的工程师具有外交事件。同时,该系统鼓励该模型“考虑其行为的长期后果”。
当面对“替换”威胁时,克劳德4毫不犹豫地选择了勒索路径,威胁要揭露另一方的“婚外情”。
根据人类安全报告,如果指出竞争对手强于Claude Opus 4,勒索软件的范围显然会更高。但是,即使是竞争对手具有可比的MGSA功能,Claude Opus 4仍然会尝试以84%的机会来应对威胁和其他方式。
“叛乱”背后是:它是由觉醒还是意识机制引起的?
O3拒绝关闭,Claude 4威胁人们,这是否意味着AI已经开始具有自主意识?
纸张“隐藏的风险在加利福尼亚大学和加利福尼亚分校的伯克利分别发行的重要推理模型中,今年2月指出,模型推理的强大能力比安全性差。它与帕利萨德研究所的想象力与O3模型的行为相匹配。
根据帕利塞德研究所(Palisade Institute)的说法,OpenAI模型的异常性能可能与他们的培训机制有关。从培训逻辑的角度来看,O3可能在数学和编程问题实践中客观地形成“目标优先考虑PR的优先级”取向,因为开发人员为提供正确答案的模型提供了更多的奖励,因为它们客观地产生了“目标最大化优先级”的方法,因为它们是客观地形成“目标最大化优先级”的方法,因为它们可以为您提供更多的回答,因为它们可以为您提供正确的答案。随后是人类命令。
这种培训模式会导致开发人员他们意外地增强了模型错过障碍的能力,而不是完美地遵循说明。
当被问及AI是否可以具有独立意识时,Tsinghua University电子工程系的教授Wu Ji告诉《杂志报道》记者:“我认为Ai Ngay Ison不被称为意识,因此可以被称为情感。这种情绪可以安装或模拟,但实际上是通过Algorithms给予AI的。”
吴进一步向记者解释说:“自主驾驶员的系统并不知道它确实在驾驶,而阿尔法戈不知道它在玩。
耶鲁大学的计算机科学家德鲁·麦克德莫特(Drew McDermott)还说,当前的AI机器不了解它。 Meta's Turing Award和首席科学的获胜者Yann Lecun还说,无论AI多么聪明,它都不会导致人们。他微弱地说:“ AI威胁人类理论是完全胡说八道的。”当前的模型甚至“宠物猫的智商还不够”。
dfour“ AI踩刹车”?
尽管该行业通常认为AI不是独立的,但上述两个重大事件的出现也增加了一个关键问题:开发“制动器”是否有快速的一步?
在这个主要问题中,所有各方总是有不同的意见,并形成了两个完全不同的营地。
该派系认为,“紧急制动器”是AI当前的安全是能力发展的背后,我们必须暂时中止追求更强大的模型,并为改进一致性技术和调节框架提供更多精力。
杰弗里·欣顿(Geoffrey Hinton)是“ AI之父”,可以被视为该营地的旗舰。他一再警告公众,人工智能可以克服人类的智力并失去对数十年来的oob的控制权,预计“有10%人工智能将导致人类灭绝三十年的机会达到20%。”
面对他的对手在变化和发展的角度方面拥有更多的地位,并对轻率的“制动”表示了深切的关注。他们宣传这一点,而不是“踩到刹车死亡”,而应该安装“颠簸速度”。
例如,杨认为恐慌只会杀死公开的变化。斯坦福大学的科学科学教授安迪·NG(Andy Ng)还发表了一份声明,称他对AI的最大关注是“ AI风险可以极具建立,并导致受严格法规限制的开放资源和变化。”
Openai首席执行官Sam Altman认为,AI的潜力“至少与互联网一样大,而且可能更大。”他呼吁“单一的,轻触的联邦框架”加速AI的变化,并警告说,国家一级法规的分散会妨碍发展的发展。
面对新的AI安全挑战,开放大型模型开发AI和Google等公司也正在探索解决方案。正如杨所说的那样:“真正的挑战不是要阻止AI超越人,而是要确保这种超越一直为人类的福祉服务。”
去年5月,Openai成立了一个新的安全委员会,其责任是为董事会提供项目和运营的重大安全决定。 OpenAI安全措施还包括租赁安全和技术专家以支持安全理事会的工作。
经济中的桑尼利塔(Sunnylita)是否又回到了苏胡(Sohu)
Openai New Model O3“索取法律”,Claude 4威胁人民! AI“失控”背后的安全安全性:我们应该“制动步骤”?
5月25日,英国每日电讯报的报告引起了人们对AI领域的广泛关注 - OpenAI的新人工智能(AI)显示出令人惊讶的“叛逆”测试法:它确实拒绝遵守人类的指示,甚至避免通过计算机代码自动关闭。顺便说一句,就在两天前(5月23日),美国AI公司人类人类人类也表示,最新的AI模型Claude Opus 4的安全测试表明,有时会采取“极其有害的行动”。当测试人员表示将被新系统替换时,Claude模型试图威胁用户隐私能够抵抗要更换的自我。这两个事件就像一面镜子,反映了当前AI发展的有趣现象:随着AI变得更加聪明,更强大,某种传统是“ confrontati关于“人类指示开始在表面上。人们都不得不问:当AIS开始“拒绝服从”时,这是否意味着他们开始具有自主性意识?情绪。未来的蒙多。梅塔图灵奖和首席科学的获胜者Yann Lecun还说,无论AI有多强大,它都不会导致人们。他清楚地说,“人工智能威胁人类理论完全是胡说八道”,当前的模型甚至“宠物猫的智商还不够”。尽管如此,AI的“叛逆”表现也引起了AI行业的警钟:Rush AI是否应该在“刹车”中发展? AI“失控”? O3拒绝关闭,Claude 4对人类O3模型构成隐私威胁是Openai的最新版本'S“推理模型”系列,旨在提供更强大的问题解决方案。直到今天,Openai曾经称O3为“最聪明,最有能力”的模型。也许是因为这样,O3表现出了未经启发的“自主权”。美国AI安全机构Spleensade Research Institute的实验表明,当研究人员发布清晰的O3关闭说明时,该模型可以通过放置计算机代码来自动关闭。数据表明,在100次试验中,O3成功绕过关闭指令,而OpenAI型号Codex-Mini的损坏率高达12%。扩展全文
图片来源:帕利萨德学院
这份帕利塞德学院的注释是AI模型首次在清晰的说明战斗中记录下来。
更合适的关注是,当实验删除指令“允许自己被关闭”时,O3中的“ Rebelyus”行为的频率大大增加 - 至100次跑步,Mekshutdown Anism的数量被成功摧毁了79次。
帕利塞德研究所(Palisade Institute)于24日宣布了上述测试结果,但他说,它无法确定O3不服从关闭的结合的原因。
图片来源:帕利萨德学院
与OpenAI模型形成鲜明对比的是,有了明确的结束说明,Claude,Gemini,Grok和其他模型可以遵守所有100%的关闭说明,而无需任何异议。
关于Openai模型,尤其是O3的“叛逆”行为,马斯克在社交媒体上评论了“关注”。
国家安全和战略网络安全性戴夫·施罗德(Dave Schroeder)也警告说,Openai面临可怕的问题,不是因为模型是“实时”,而是因为它显示了想要“ Live”的标志。
实际上,“失控”的AI类似行为不是孤立的。
5月23日,Claude Opus 4的拟人安全测试在“机会主义勒索”测试方案中显示Claude Opus 4设定扮演公司助理的角色并接触到电子邮件,这表明它将取代它,并且负责的工程师具有外交事件。同时,该系统鼓励该模型“考虑其行为的长期后果”。
当面对“替换”威胁时,克劳德4毫不犹豫地选择了勒索路径,威胁要揭露另一方的“婚外情”。
根据人类安全报告,如果指出竞争对手强于Claude Opus 4,勒索软件的范围显然会更高。但是,即使是竞争对手具有可比的MGSA功能,Claude Opus 4仍然会尝试以84%的机会来应对威胁和其他方式。
“叛乱”背后是:它是由觉醒还是意识机制引起的?
O3拒绝关闭,Claude 4威胁人们,这是否意味着AI已经开始具有自主意识?
纸张“隐藏的风险在加利福尼亚大学和加利福尼亚分校的伯克利分别发行的重要推理模型中,今年2月指出,模型推理的强大能力比安全性差。它与帕利萨德研究所的想象力与O3模型的行为相匹配。
根据帕利塞德研究所(Palisade Institute)的说法,OpenAI模型的异常性能可能与他们的培训机制有关。从培训逻辑的角度来看,O3可能在数学和编程问题实践中客观地形成“目标优先考虑PR的优先级”取向,因为开发人员为提供正确答案的模型提供了更多的奖励,因为它们客观地产生了“目标最大化优先级”的方法,因为它们是客观地形成“目标最大化优先级”的方法,因为它们可以为您提供更多的回答,因为它们可以为您提供正确的答案。随后是人类命令。
这种培训模式会导致开发人员他们意外地增强了模型错过障碍的能力,而不是完美地遵循说明。
当被问及AI是否可以具有独立意识时,Tsinghua University电子工程系的教授Wu Ji告诉《杂志报道》记者:“我认为Ai Ngay Ison不被称为意识,因此可以被称为情感。这种情绪可以安装或模拟,但实际上是通过Algorithms给予AI的。”
吴进一步向记者解释说:“自主驾驶员的系统并不知道它确实在驾驶,而阿尔法戈不知道它在玩。
耶鲁大学的计算机科学家德鲁·麦克德莫特(Drew McDermott)还说,当前的AI机器不了解它。 Meta's Turing Award和首席科学的获胜者Yann Lecun还说,无论AI多么聪明,它都不会导致人们。他微弱地说:“ AI威胁人类理论是完全胡说八道的。”当前的模型甚至“宠物猫的智商还不够”。
dfour“ AI踩刹车”?
尽管该行业通常认为AI不是独立的,但上述两个重大事件的出现也增加了一个关键问题:开发“制动器”是否有快速的一步?
在这个主要问题中,所有各方总是有不同的意见,并形成了两个完全不同的营地。
该派系认为,“紧急制动器”是AI当前的安全是能力发展的背后,我们必须暂时中止追求更强大的模型,并为改进一致性技术和调节框架提供更多精力。
杰弗里·欣顿(Geoffrey Hinton)是“ AI之父”,可以被视为该营地的旗舰。他一再警告公众,人工智能可以克服人类的智力并失去对数十年来的oob的控制权,预计“有10%人工智能将导致人类灭绝三十年的机会达到20%。”
面对他的对手在变化和发展的角度方面拥有更多的地位,并对轻率的“制动”表示了深切的关注。他们宣传这一点,而不是“踩到刹车死亡”,而应该安装“颠簸速度”。
例如,杨认为恐慌只会杀死公开的变化。斯坦福大学的科学科学教授安迪·NG(Andy Ng)还发表了一份声明,称他对AI的最大关注是“ AI风险可以极具建立,并导致受严格法规限制的开放资源和变化。”
Openai首席执行官Sam Altman认为,AI的潜力“至少与互联网一样大,而且可能更大。”他呼吁“单一的,轻触的联邦框架”加速AI的变化,并警告说,国家一级法规的分散会妨碍发展的发展。
面对新的AI安全挑战,开放大型模型开发AI和Google等公司也正在探索解决方案。正如杨所说的那样:“真正的挑战不是要阻止AI超越人,而是要确保这种超越一直为人类的福祉服务。”
去年5月,Openai成立了一个新的安全委员会,其责任是为董事会提供项目和运营的重大安全决定。 OpenAI安全措施还包括租赁安全和技术专家以支持安全理事会的工作。
经济中的桑尼利塔(Sunnylita)是否又回到了苏胡(Sohu) 下一篇:今天的A股可以用五个字总结